Scraping The Prizepool
Ibrahim Saberi
June 24, 2019
Grabbing Cash From TI9
Okay. I’m not actually taking anything from The International 2019 prizepool (if I could, I’d detail that in a separate blog post probably). However, in the OpenDota discord someone did pose this question:

If you follow TI at all, you’ll likely know about the prizepool trackerIn writing this blog post I learned that this website is served over HTTP. For shame. that’s run by Cyborgmatt. I had always assumed that he had access to some internal API that allowed him to poll and collect that data in half hour increments:
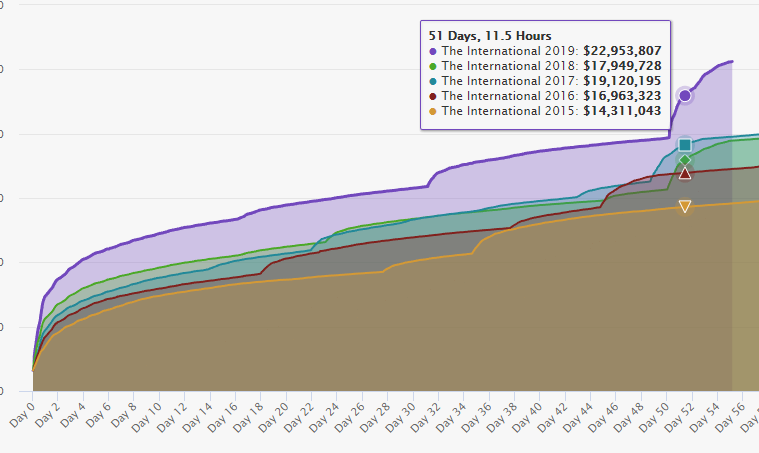
I actually got curious to see what would happen if I tried to access this page over HTTPS instead of HTTP. The results, are, well…
And since dota2 is a subdomain, I wondered what would happen if I went to the regular prizetrac.kr domain.
…hm.
I didn’t spend too much time figuring out how exactly the data is populated on the dota2.prizetrac.kr site. My first destination was the Network tab in Chrome DevTools. The only data loaded via XHR were some milestone related data and another set to be used for searching(?) different tournaments:
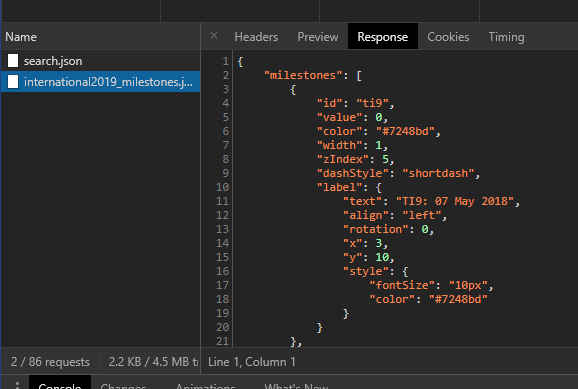
Literally_Nothing.png
The prize tracker website uses HighCharts for its interactive charts. I checked the actual page source to see how the data was being inserted into the charts:
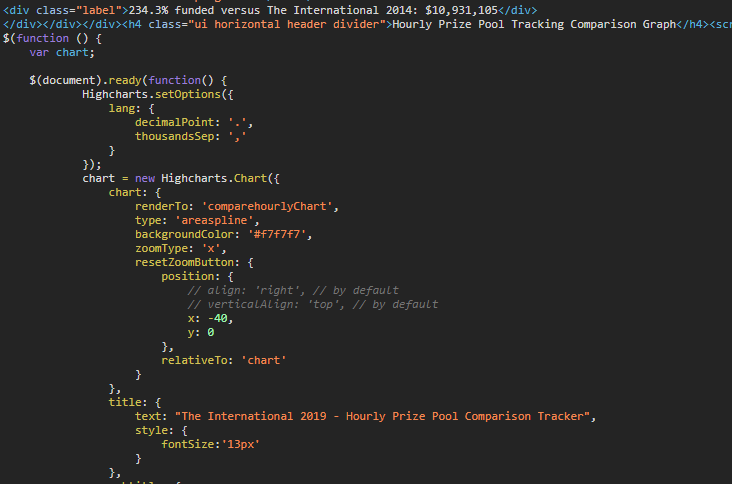
And lo and behold:
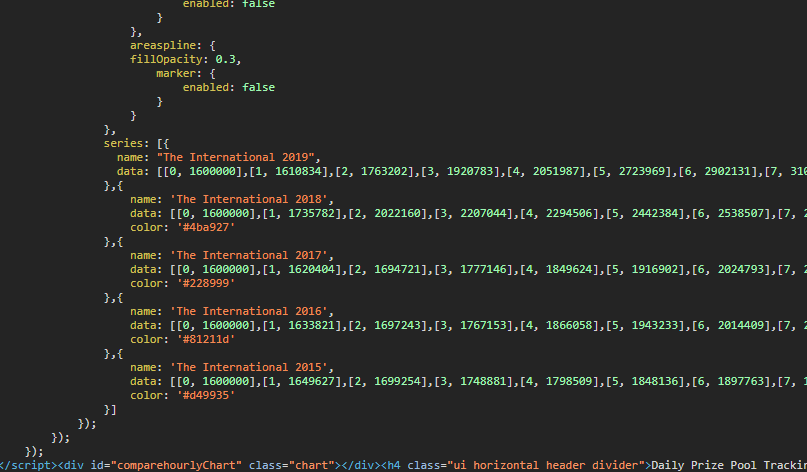
So I’m guessing that either server-side there’s something pulling the dataFrom… somewhere… and then embedding it before the page is served or the webpage (aka the internal array) is being updated literally every half hour. Probably the latter?
Finding Another Way
So you could probably just take this data from the prize tracker site if you wanted, especially since I’m not sure where else you could find historical prize pool data for every half hour.
What I want to do is take The International Battlepass pageAlso served by default over HTTP? What the heck Volvo? At least it redirects properly when forcing HTTPS… , scrape that page for the prize pool presented there (you have to wait about half an hour before the actual number displays even though it’s already in the DOM tree… because reasons), and then populate it here.
Scraping it is pretty easy. The div holding the prize pool doesn’t have an id, but it does have a unique class with a data-text attribute that holds the amount:
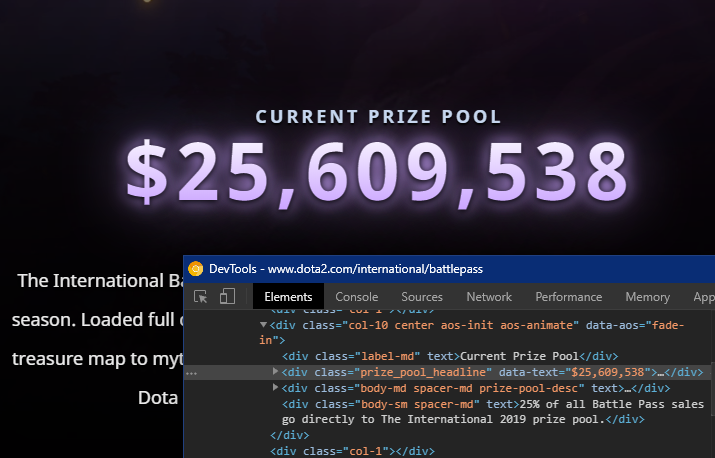
Assuming I have access to the DOM tree because I’ll be able to grab a valid XML documentForeshadowing. I can simply just:
const dota2website = //some XMLHttpRequest responseXML object
const prizepoolElement = dota2website.getElementsByClassName("prize_pool_headline")[0];
const prizepool = prizepoolElement.dataset.text;
Next question is how you get past all those pesky cross-origin request “HEY THAT’S ILLEGAL” shenanigans. There’s a cool proxy that allows you to append whatever website that will bypass all this stuff for you; it’s called cors-anywhere. So, uh, I’ll use that.
I set up my script:
let getPrizePool = (url) => {
if(!window.XMLHttpRequest) return;
let xhr = new XMLHttpRequest();
xhr.onload = (event) => {
if(callback && typeof(callback) === 'function') {
callback(xhr.responseXML);
}
}
xhr.open('GET',url);
xhr.send();
}
const url = 'https://cors-anywhere.herokuapp.com/https://www.dota2.com/international/battlepass';
getPrizePool(url, (res) => {
const dota2website = res;
const prizepoolElement = dota2website.getElementsByClassName("prize_pool_headline")[0];
const prizepool = prizepoolElement.dataset.text;
});
And with that you should have the prizepool! You open an XMLHttpRequest to the battlepass website, pass the XML Document response object to a callback, and then do all the other stuff.
Except. Well. This doesn’t work.
As it turns out, responseXML doesn’t ever get set because the return object isn’t considered valid XML! Definitely didn’t see that one coming. I tried reparsing the basic response object as XML using the DOMParser interface, but it breaks pretty early into the file and I get this:
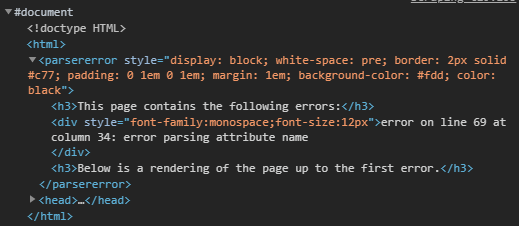
That’s pretty early on? What’s happening in this document?
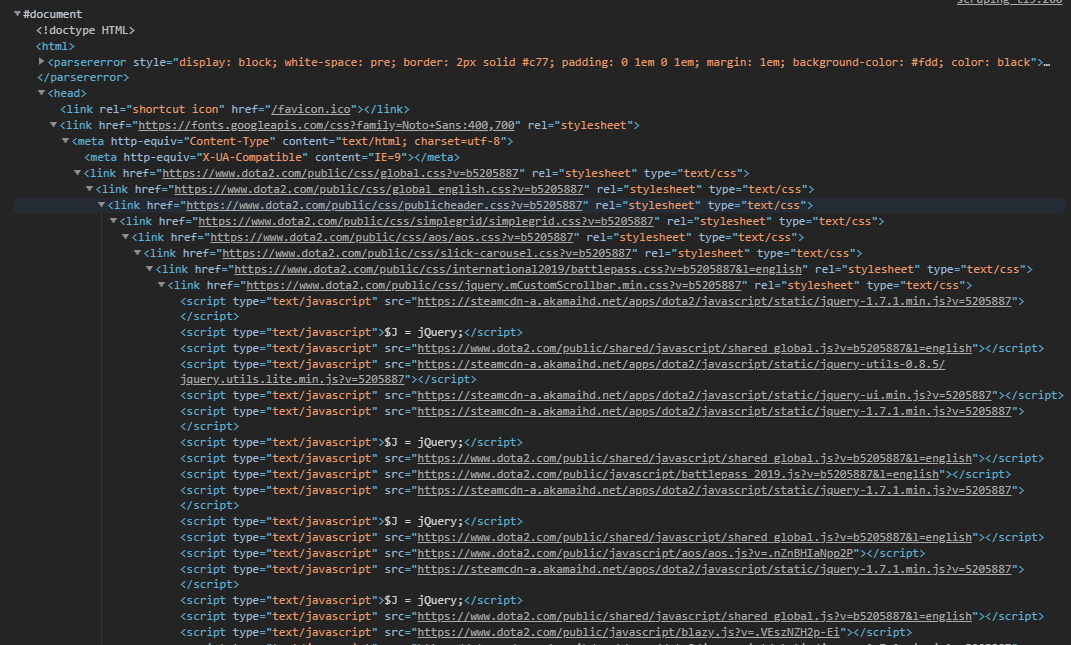
Uhhhhhhh… What the hell?
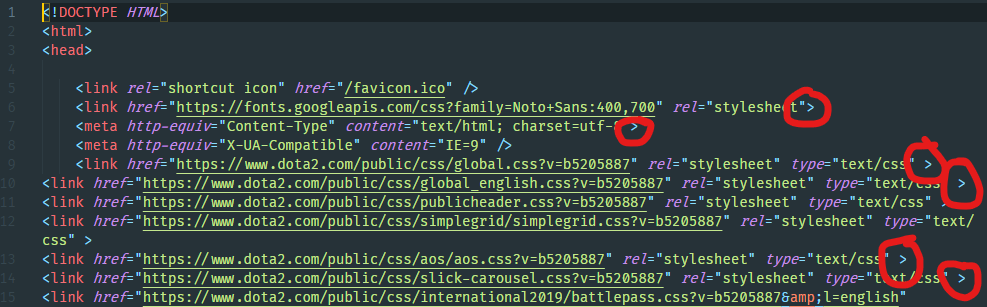
Oh. I see.
A note to all web developers out there. Please put trailing slashes where needed in your web documents. You know, so I can scrape them easily.
Pretty please.
Anyway, I don’t believe that was the actual issue that DOMParser faced, and it more had to do with the <script> tag that appears where it stops parsing. Can’t do much about that.
Alright… What Now?
You know what they say you do when all else fails?
Yeah, that’s right. It’s regex time.
The regex here is actually incredibly simple. Like so simple that I figured it out. And I straight up bombed the regex unit in my Rapid Prototyping class. That’s the one unit you’re not supposed to fail. Like ever.
Enough reminiscing.
Our expression prize_pool_headline appears twice in the response object. The first time is for some dumb javascript stuffIn fact, the same dumb javascript stuff that broke the XML doc in the first place! How quaint. , and the second is the one we want. So we simply match that plus the end of the div:
const regex = /prize_pool_headline">/gm;
But we need all that junk after the headline too. We can use a capture group for this:
const regex = /prize_pool_headling">(.*)/gm;
const match = regex.exec(xhr.response);
let prizepool = match[1]; // this will give you '$25,XXX,XXX</div>'
And then you strip out that last </div> and then you’re done! You can throw the resulting prizepool into whatever as needed:
prizepool = prizepool.substr(0, prizepool.indexOf("</div>"));
let poolDiv = document.getElementById("prizepool");
poolDiv.innerHTML = prizepool;
The current prizepool for The International 2019 is:
EDIT MAY 29, 2020: The TI10 Battlepass is here! This means that this code no longer works, but I can certainly recreate it for future battlepasses. I can. I probably won’t. Just trust me, this used to work.
If you’re interested, you can see the full script in the source of this page!